Scaling Global AI Inference with NATS JetStream


GPU time is expensive. Wasting it because your inference pipeline can’t absorb a traffic spike is worse.
NATS + JetStream solves this, even at the scale of the biggest companies in the world. NVIDIA’s Cloud Functions platform (NVCF) runs on a Synadia-managed NATS supercluster. JetStream provides the durable, low-latency work queue that decouples bursty HTTP/gRPC traffic from GPU capacity across multiple regions. That architecture enables scale-to-zero, multi-region failover, and clean per-function isolation for every inference workload running on NVCF.
The pattern isn’t unique to NVIDIA. Any team running inference at scale hits the same fundamental mismatch: traffic is bursty and global, GPUs are expensive and finite. Coupling requests directly to workers leads to overload, dropped requests, or wasted capacity. The fix is a messaging layer that absorbs the variance.
The Problem: Bursty Demand, Scarce GPUs
AI inference workloads share a few tough characteristics:
- Sudden traffic spikes from product launches, viral events, or batch jobs
- Global users who expect low latency
- GPU clusters that cost a fortune and can’t scale instantly
- A hard requirement for reliability, retries, and backpressure
Directly hitting GPU workers with raw HTTP or gRPC traffic breaks down fast. What you actually need is decoupling: absorb bursts somewhere durable, schedule work to GPUs based on real-time capacity, and retry failed jobs automatically.
How NATS + JetStream Fits
NATS is a high-performance messaging system built for real-time workloads. JetStream adds durability, acknowledgements, and replay on top of Core NATS, giving you a distributed work queue and streaming system in one.
For inference pipelines, the notable capabilities are:
- Microsecond-level messaging latency for fast request routing
- Durable streams that buffer traffic when GPU workers are saturated
- At-least-once delivery with explicit acks, so nothing gets silently dropped
- Flow control and backpressure to protect workers from being overwhelmed
- Multi-region topologies (superclusters, leaf nodes, stream mirrors) for global routing and data locality
This is exactly how NVCF operates: a global NATS supercluster with JetStream streams per function, giving each inference workload its own isolated queue with independent backpressure and scaling behavior.
The Inference Architecture
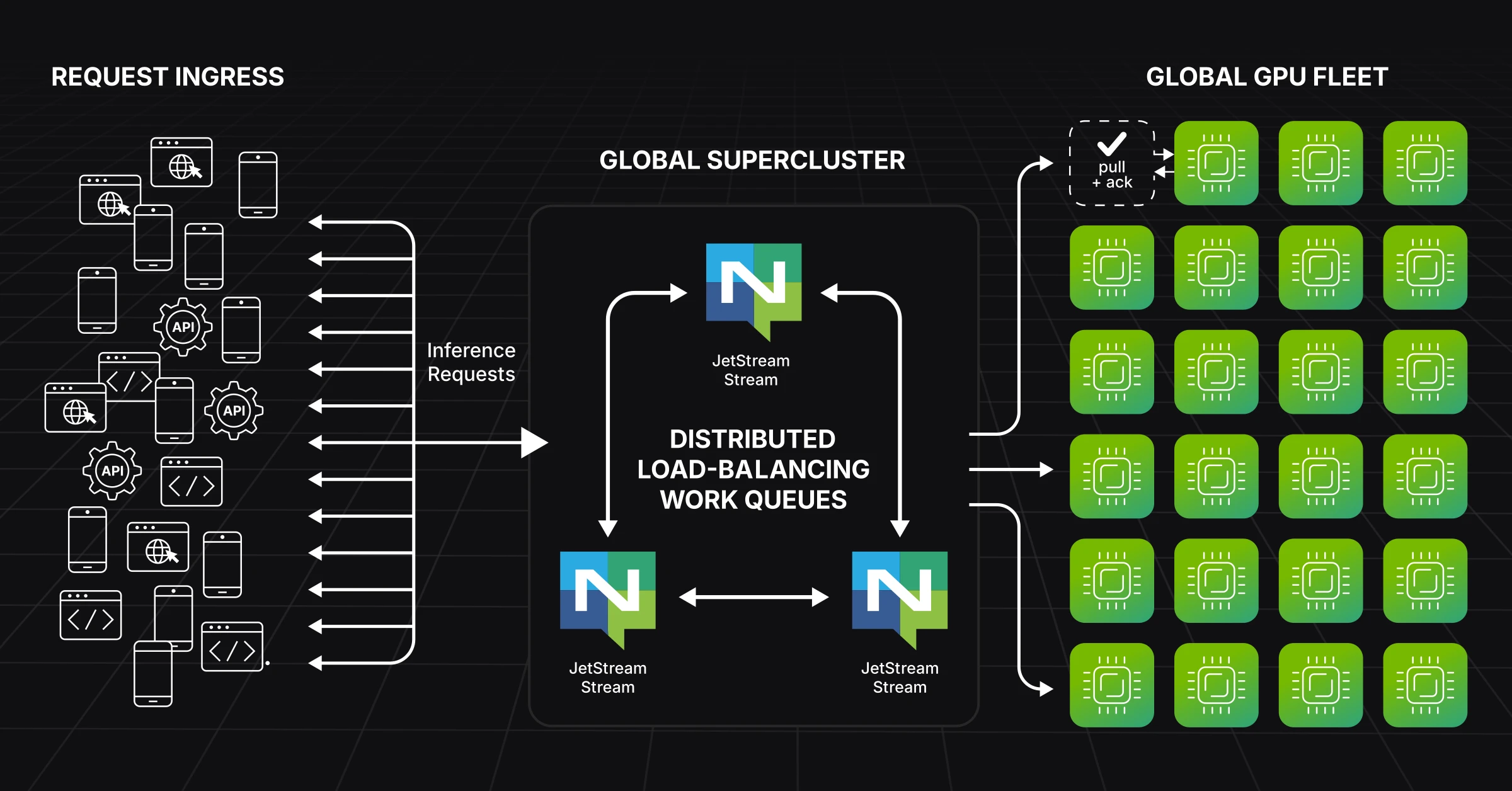
GPU workers consume inference requests using pull-based JetStream consumers with explicit acknowledgements. Each worker only pulls a new job when it has available GPU capacity. The worker controls the pace, not the producer. That creates natural backpressure without any external rate-limiting logic.
If a worker crashes mid-inference or stalls, it never sent the ack. JetStream notices and redelivers the job to another available GPU. No custom retry logic, no dead-letter queue plumbing. It’s built into the protocol.
Across regions, NATS Superclusters route requests to the nearest available fleet, while JetStream mirrors critical streams for resilience and failover. When no GPU workers are active for a given function, the stream simply buffers requests until capacity comes online. That’s how you get true scale-to-zero without losing a single request.
What Pull-Based Consumption Changes
The shift from push to pull is worth dwelling on, because it changes the operational model.
When workers pull work instead of being pushed requests, GPU capacity becomes a first-class control signal. Workers that are busy don’t receive more work. Workers that are idle pull immediately. There’s no external scheduler deciding who gets what. The queue and the workers negotiate it naturally through the pull/ack cycle.
The practical result: higher GPU utilization without overload, automatic retries on failure, and global scalability without custom routing logic. Instead of building separate queueing, scheduling, and failover systems, NATS handles all three.
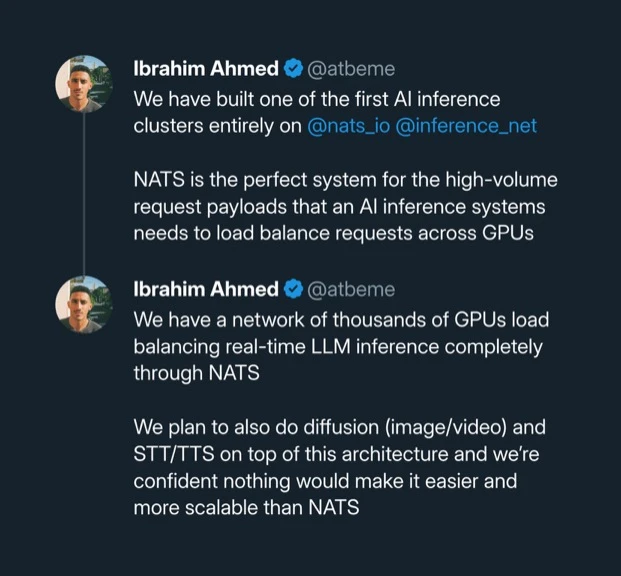
This pattern scales from small teams to some of the largest inference platforms in production. inference.net built their production inference cluster entirely on NATS, load balancing real-time LLM requests across thousands of GPUs globally.
Where to Go from Here
NVIDIA runs this pattern in production across NVCF. So does inference.net. If you’re designing inference systems, the distributed messaging layer is a solved problem.
For teams that want help operating their global NATS infrastructure, whether you want our expertise to move faster or want us to manage your NATS cluster end-to-end, let’s talk.
Related posts
All posts


