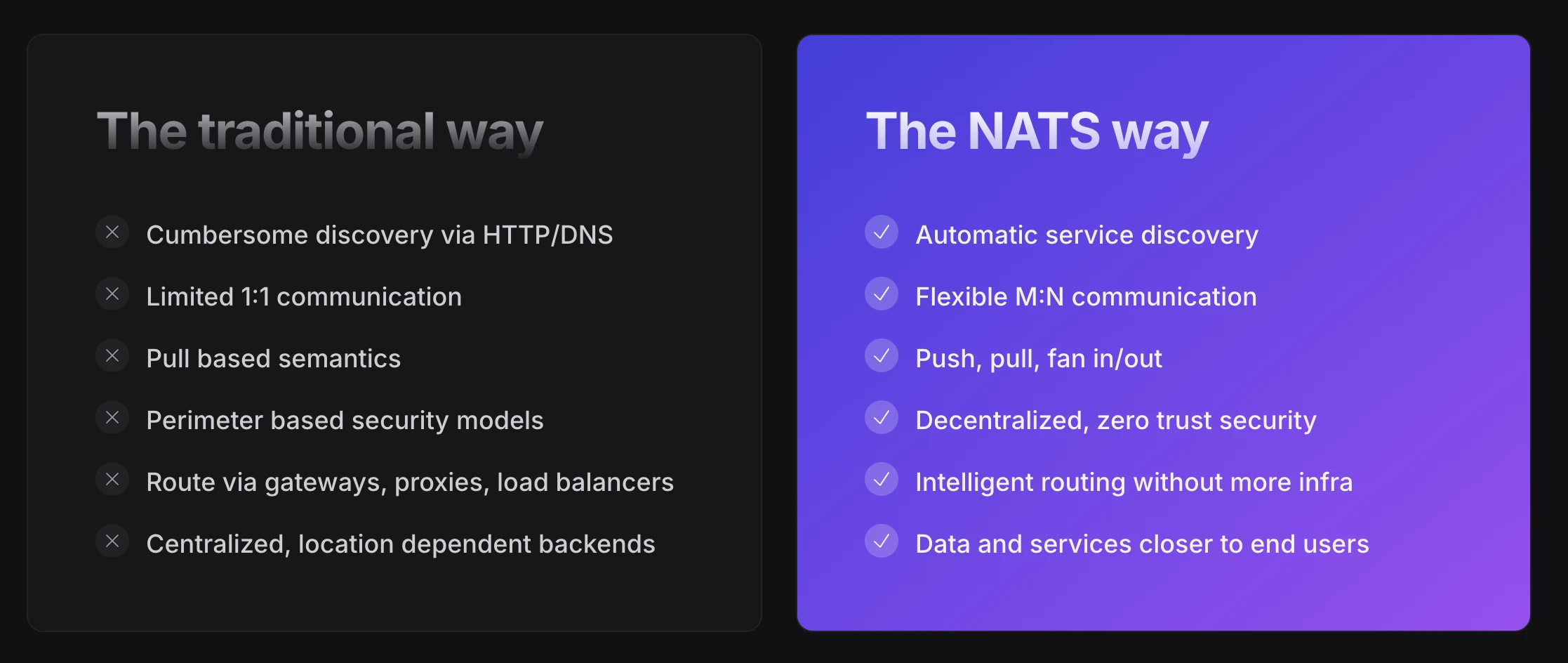
Why NATS


If you’re building distributed systems today, you’re likely dealing with a familiar challenge: a sprawling collection of specialized tools, each solving a piece of the puzzle.
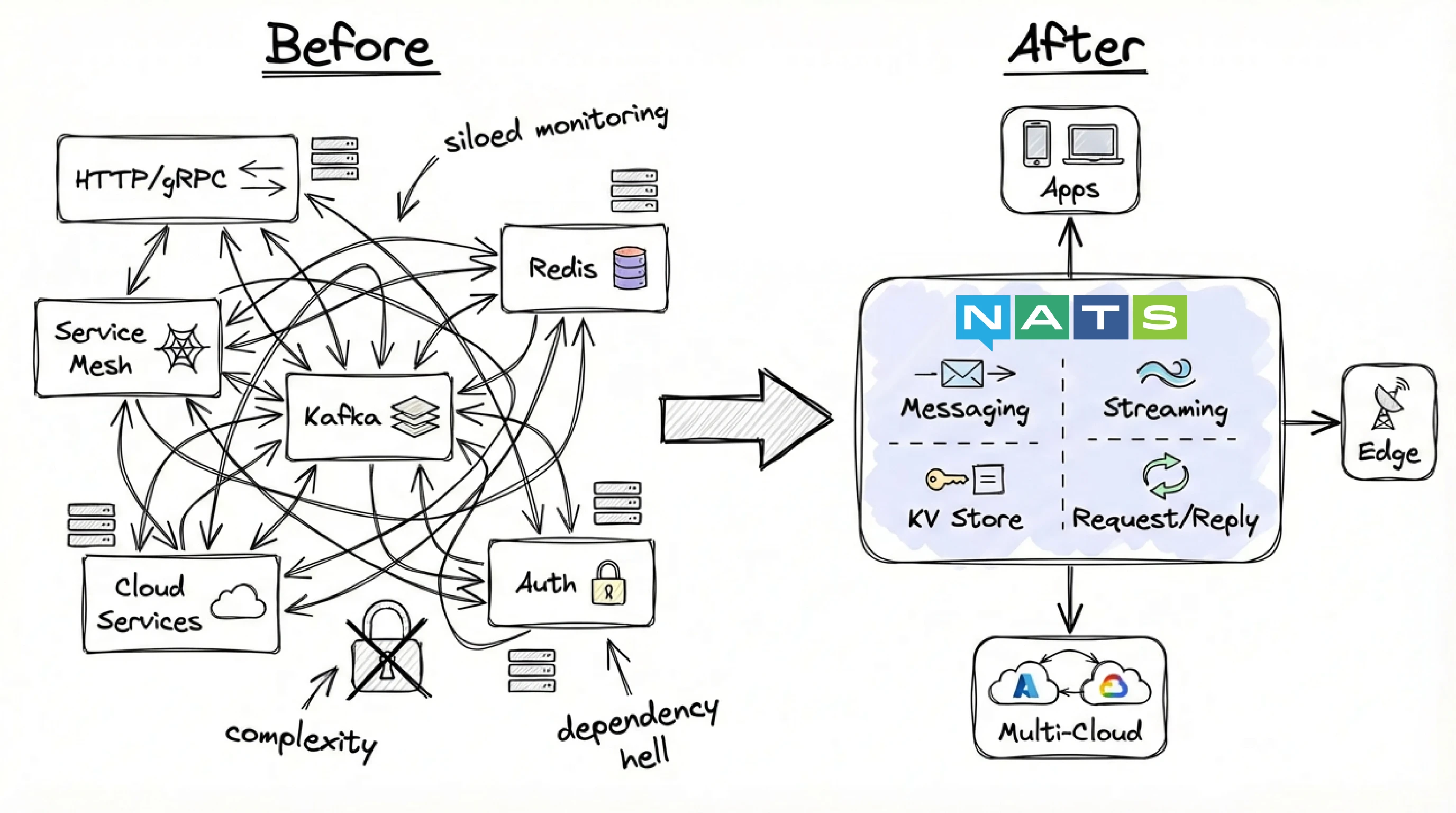
HTTP or gRPC for service communication, a service mesh like Consul for discovery, Kafka or Redpanda for streaming, Redis for caching, plus a variety of managed cloud services to tie them all together. Each tool requires its own expertise to operate, secure, and integrate. The result? Complexity that compounds at every layer.
NATS.io takes a different approach. Rather than adding another tool to the stack, it consolidates the functionality of multiple systems into a single piece of infrastructure. It can handle messaging (pub/sub, request/reply), streaming with persistence, key-value, and object storage, while spanning multiple clouds and extending to the edge. The topology can be adapted dynamically without requiring changes to applications.
Different Foundations
Most distributed systems are built on foundational assumptions that are familiar, but actually introduce complexity as they are built upon. These aren’t implementation details that can easily be abstracted away. Attempts to do so often increase complexity further.
NATS addresses this by treating these concerns as first-class design constraints, not accidental byproducts:
- Location independence
- M:N communication
- Asynchronous-first interactions
Location independence
As consumers of the Web (reading this blog), we are familiar with the concept of IP addresses and DNS. We type in an address and it goes through one or more layers of resolution. When services move, scale, or failover, the discovery layer must be updated. Proxies and/or load balancers are the typical solution to add indirection to routing to services. However, they add latency, configuration overhead, and potential points of failure. Additionally, configuration or registration changes are required every time a service is added before it is addressable. Location dependence permeates this architecture.
With NATS, clients connect to the NATS server and simply subscribe to the subjects they are making one or more services available on. That is it. No load balancers, no DNS, no sidecars with automatic service registration. Better yet, by using the service API (built into official client SDKs), you get a discoverable registry for free. You can list all registered services, retrieve basic stats for a given service, and query info, such as endpoints.
Publishers don’t need to know where subscribers are located, how many exist, or whether they’re currently running. The NATS infrastructure handles routing. Services can move between hosts, scale horizontally, or fail over without any changes to other services. No load balancer configuration, no DNS updates, no service mesh policies. Location independence replaces discovery complexity.
Once a client is connected to a NATS system, messages will traverse any topology to interested clients even if the topology changes dynamically. NATS provides real location independence.
M:N communication
The most familiar interaction pattern is request/reply. Unfortunately, many system designers take that at face value when choosing technologies that are limited to point-to-point (1:1) communication.
For service-to-service communication, the dominant protocols used are HTTP and gRPC (HTTP under the covers). The sending service is the client to the receiving service. The happy path for service-to-service communication is the chain of requests that ultimately result in the origin client (i.e. a device, Web browser, CLI, etc). The key limitation of 1:1-only protocols is that passive observation isn’t possible. Adding observers for logging, debugging, or analytics requires additional infrastructure. The 1:1 communication model limits architectural flexibility.
With NATS, M:N is the default. This means any number of publishers and subscribers (read senders and receivers) can be multi-plexed over the same subject. Adding a new subscriber doesn’t require modifying the publisher. Passive observation is built-in for use cases like audit logging, debugging, and analytics. The M:N communication model provides flexibility that 1:1-only technologies can’t match.
Asynchronous-first interactions
With 1:1 communication comes the expectation that the receiver of a message is available. Of course this is necessary for interactions that are intentionally request-reply. However, that is not the only interaction model necessary for a distributed system. This is inherently why additional infrastructure dependencies get added into the mix when HTTP/gRPC-based service architectures are designed.
The topic of synchrony is very nuanced and is an overall system design concern. With NATS, you have all the choices built into one technology.
With NATS’ messaging patterns (combined with location independence), you get spatial decoupling of pub/sub, request/reply, and request/reply-many that is not limited to a specific cluster or region.
With NATS’ streaming capabilities, you get temporal decoupling where messages can be published and stored in a persistent stream that a client/service can consume when it is available and at its own rate.
These foundational differences have led to not only more options and flexibility for building systems, but avoiding needing to introduce additional infrastructure.
The Adoption Pattern
“Nothin’ but NATS” has been an internal phrase for years, articulating the project’s scope: provide infrastructure for building distributed systems without integrating multiple specialized tools.
A common pattern we observe: teams adopt NATS to solve a single problem, then expand usage over time. The initial use case is typically narrow—replacing an existing message broker or adding pub/sub to a microservices architecture.
As teams explore further, they realize NATS addresses problems they’ve been solving with separate tools. “Nothin’ but NATS” begins to resonate with them.
HTTP-based service communication? NATS handles it with lower latency and built-in request/reply. A Kafka cluster for streaming telemetry? JetStream provides similar capabilities with simpler operations. Redis for distributed counters and caching? The key-value store offers comparable functionality as part of the same infrastructure.
Instead of managing five or six systems—each with its own authentication model, monitoring approach, and operational playbook—teams consolidate. The reduction in complexity translates to lower costs, fewer moving parts, and less integration work.
This isn’t vendor lock-in. It’s recognizing that platform coherence has value.
Different Roles, Single Platform
Distributed systems require collaboration across developers, architects, and operations teams. NATS provides capabilities for each role rather than optimizing for just one.
Developers can use a single client SDK in their preferred language to access messaging, streaming, key-value, and object storage APIs. The authentication schemes and API patterns are consistent across all capabilities, whether publishing events, storing state, or implementing request/reply patterns.
Architects can design topologies that span multiple clouds and geographies without interrupting existing workloads. NATS’ leafnode and supercluster capabilities allow adding new regions or extending to edge locations without downtime. The system topology can change over time rather than requiring upfront design decisions that are difficult to change later.
Operators work with a single platform that includes multi-tenancy, decentralized security, and built-in monitoring. Rather than integrating authentication and authorization across multiple systems, NATS provides a consistent model with subject-level permissions and optional entitlements. Likewise, NATS monitoring endpoints provide a rich set of data enabling robust observability of the system.
More Than a Message Broker
People familiar with NATS from 2011 remember it as the single-tenant, at-most-once delivery message broker that powered Cloud Foundry. That version had basic clustering support and focused on low-latency pub/sub messaging. Modern NATS is substantially different.
Two releases fundamentally changed what NATS could do.
NATS 2.0 (2019)
The 2.0.0 release introduced multi-tenancy, allowing a single NATS infrastructure to securely serve multiple teams or applications with isolation and resource controls. It included a decentralized authentication and authorization model that scales without centralized management.
This release also introduced superclusters (multi-region and multi-cloud topologies) and leafnodes (hub-and-spoke edge deployments). These features extended NATS beyond single datacenter deployments, making it viable for distributed architectures spanning multiple cloud providers and edge locations.
NATS 2.2 (2021)
The 2.2.0 release added JetStream, a persistence subsystem providing at-least-once delivery and exactly-once processing semantics. This expanded NATS into streaming and event sourcing use cases.
This release also included native WebSocket support (enabling NATS clients to run in browsers) and MQTT 3.1.1 support (bridging IoT devices and MQTT-only clients into NATS systems).
These two releases position NATS differently than traditional message brokers. It addresses the broader challenge of distributed systems connectivity rather than solving a single narrow use case. When evaluating NATS, the comparison isn’t just against message brokers or streaming platforms, but against the combination of tools typically used to build distributed systems.
Why NATS is Different
Kafka is optimized for high-throughput ingestion. Redis for in-memory data structures. RabbitMQ for complex routing. Each excels at its specific purpose—but each also inherits assumptions (point-to-point addressing, synchronous expectations, location-dependent routing) that limit where and how it can be deployed.
NATS’ foundational choices—location independence, M:N communication, async-first design—aren’t just features. They’re what allow a single system to span use cases that typically require separate tools. The same primitives that enable pub/sub also enable request/reply, streaming, and key-value storage without architectural contortion.
The tradeoff: NATS may not be the most optimized for any single narrow use case. But it handles the 80% of features you actually use through consistent APIs and one operational surface, rather than forcing you to integrate 100% of features across fragmented systems where most go unused.
This is especially relevant for edge deployments
Intermittent connectivity, diverse runtimes, fleet management, and low-resource environments present challenges for technology and systems built on cloud-centric assumptions. NATS’ leafnodes, asynchronous replication, and small footprint aren’t bolted-on edge features—they’re natural extensions of the same async-first, location-independent design.
Getting Started
NATS addresses common distributed systems requirements: spanning clouds, connecting services, managing state, streaming events, and extending to the edge. It does this through a single platform rather than requiring integration of multiple specialized tools.
This approach isn’t optimal for every single use case. But for the majority of distributed systems architectures, NATS provides the capabilities needed while significantly reducing operational complexity. And if you need to integrate with a more specialized tool, that is always possible.
NATS is fully open source, incubating in the CNCF, and has extensive documentation, examples, and a very active community.
Synadia provides a variety of commercial products and services, including:
- Synadia Education - Instructor-led training courses for NATS developers and administrators
- Synadia Cloud - A multi-tenant SaaS backed by a global NATS supercluster
- Synadia Deploy for Kubernetes - Simplified NATS & Synadia Platform deployment for Kubernetes
- Synadia Platform - Self-managed or fully-managed Bring Your Own Cloud (BYOC) NATS deployments with expert support, including additional Synadia developed components
If you’re just starting your NATS journey—or already deep into it—and think Synadia can help, reach out to us.
Related posts
All posts


