Orbit.go: A Guide to NATS Client-Side Abstractions for Go

In our previous post about Orbit, we introduced it as the umbrella project for client-side abstractions which are above the NATS protocol level or need incubation before being incorporated. Since the initial announcement, Orbit libraries have grown significantly with new modules and enhancements, addressing specific challenges developers face when building distributed systems with NATS.
Today, we’re exploring orbit.go in depth - going through all currently available modules that extend the nats.go client, exploring their capabilities, possible use cases and how they can simplify your NATS-based applications.
Installation and Getting Started
To start using orbit.go, we recommend visiting the repository on GitHub and going through the list of available modules - each living in a separate directory with comprehensive documentation and examples.
Installing orbit.go modules is straightforward – each of them is independently versioned and can be imported as needed:
# Install individual modules as neededgo get github.com/synadia-io/orbit.go/natsextgo get github.com/synadia-io/orbit.go/jetstreamextgo get github.com/synadia-io/orbit.go/counters# ... and so onSince each module is independent, you only pull in the dependencies you actually need. This approach keeps your application lean while giving you access to powerful abstraction without pulling in unnecessary dependencies (dependencies are isolated per module).
As maintainers, this also means we can iterate faster, releasing new features and improvements as each module evolves or new modules are introduced.
NATS Server 2.12: New Features, New Possibilities
With NATS server 2.12, we’ve introduced several features that open up new design patterns.
For details on these features, visit the NATS 2.12 Release Blog. Two standout capabilities that orbit.go exposes are distributed counters and atomic batch publishing.
The counters module leverages the server’s new AllowMsgCounter capability to provide distributed counter CRDT (Conflict-free Replicated Data Type). Meanwhile, atomic batch publishing in the jetstreamext module ensures that either all messages in the batch are published or none at all.
While the configuration for these features happens at the nats.go StreamConfig level, orbit.go provides intuitive APIs to interact with them, abstracting away the underlying complexity.
Going forward, we expect many more client-side abstractions to land in Orbit, allowing the community to experiment, provide feedback, and help shape these features. While client-side abstractions will stay in orbit, some feature extensions may graduate to main clients.
Core Extensions: Building on the Fundamentals
natsext - Enhancing Core NATS
Let’s start with the basics. The natsext module provides essential extensions to core NATS functionality. Currently it exposes RequestMany, enabling waiting for multiple responses to a single request, which is perfect for scatter-gather patterns or streaming responses.
RequestMany provides an iterator-based API that allows you to process responses as they arrive, without needing to buffer them all in memory. A request can have various termination conditions, such as a timeout, maximum number of responses or even a custom predicate.
When to use: When you need scatter-gather patterns, service discovery, or collecting responses from multiple subscribers. Perfect for health checks across service instances or aggregating data from distributed sources.
When to avoid: For simple request-reply patterns with a single responder - stick to standard NATS request-reply.
1// Send one request, await multiple responses2ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)3defer cancel()4
5msgs, err := natsext.RequestMany(ctx, nc, "service.status", []byte("health"))6if err != nil {7 return err8}9
10for msg, err := range msgs {11 if err != nil {12 log.Printf("Error receiving response: %v", err)13 continue14 }15 fmt.Printf("Service response: %s\n", string(msg.Data))16}jetstreamext - Extending JetStream
The jetstreamext module is where things get really interesting, building on top of JetStream to provide advanced capabilities like atomic batch publishing and batch message retrieval.
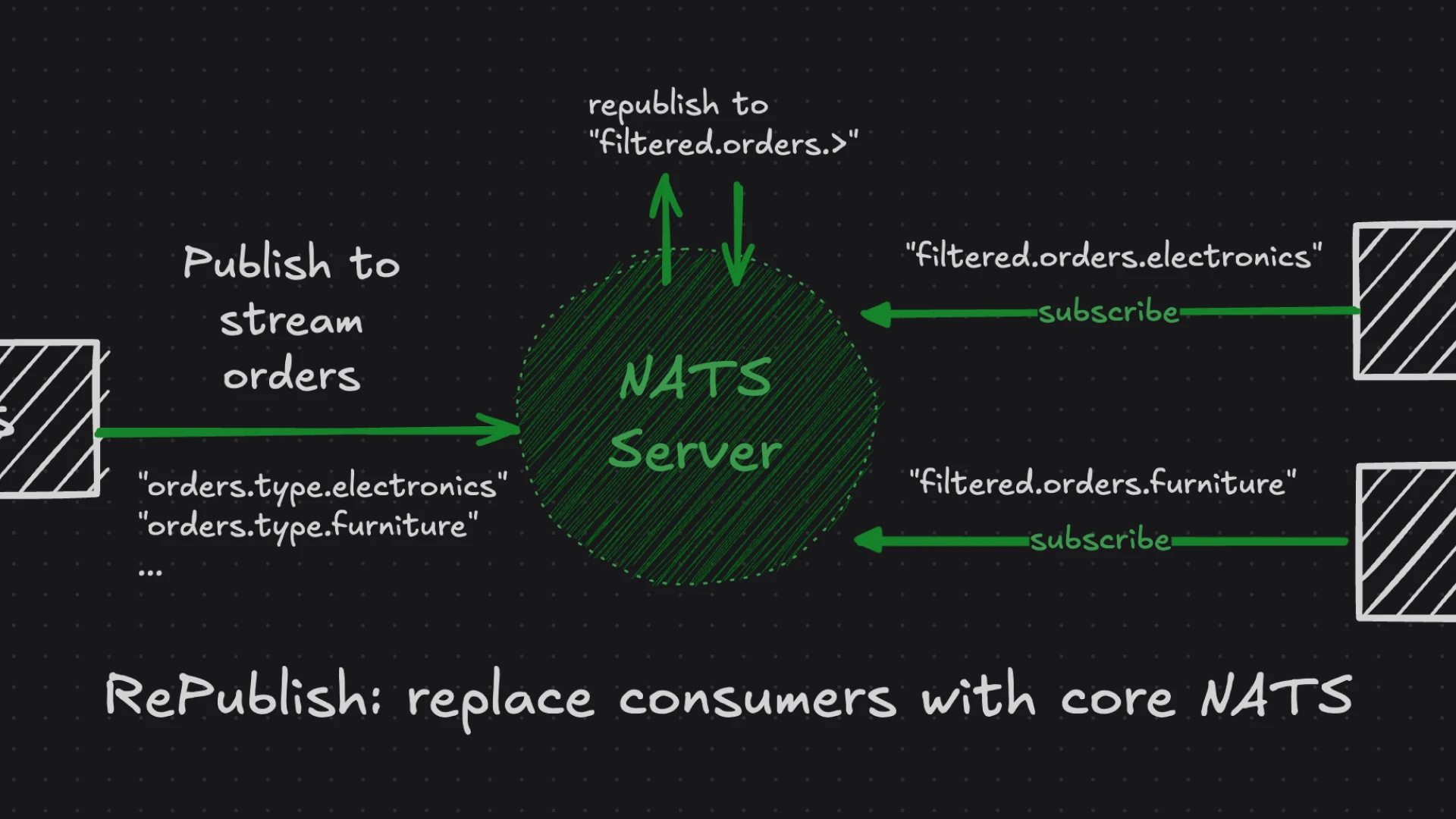
Atomic Batch Publishing
Atomic batch publishing allows you to group multiple messages into a single atomic operation. This means that either all messages in the batch are successfully stored in JetStream, or none are, ensuring consistency.
When to use: When you need atomic multi-message operations, ensuring either all messages are stored or none are. Examples include financial transactions, order processing, event sourcing, or any scenario where separate messages are desired for downstream processing, but partial writes could lead to inconsistencies. Also, use it to reduce round-trips to the server in high-throughput cases with large batches.
When to avoid: For message publishing where atomicity is not a concern, or when wanting to make use of message deduplication (which is not compatible with batch publishing).
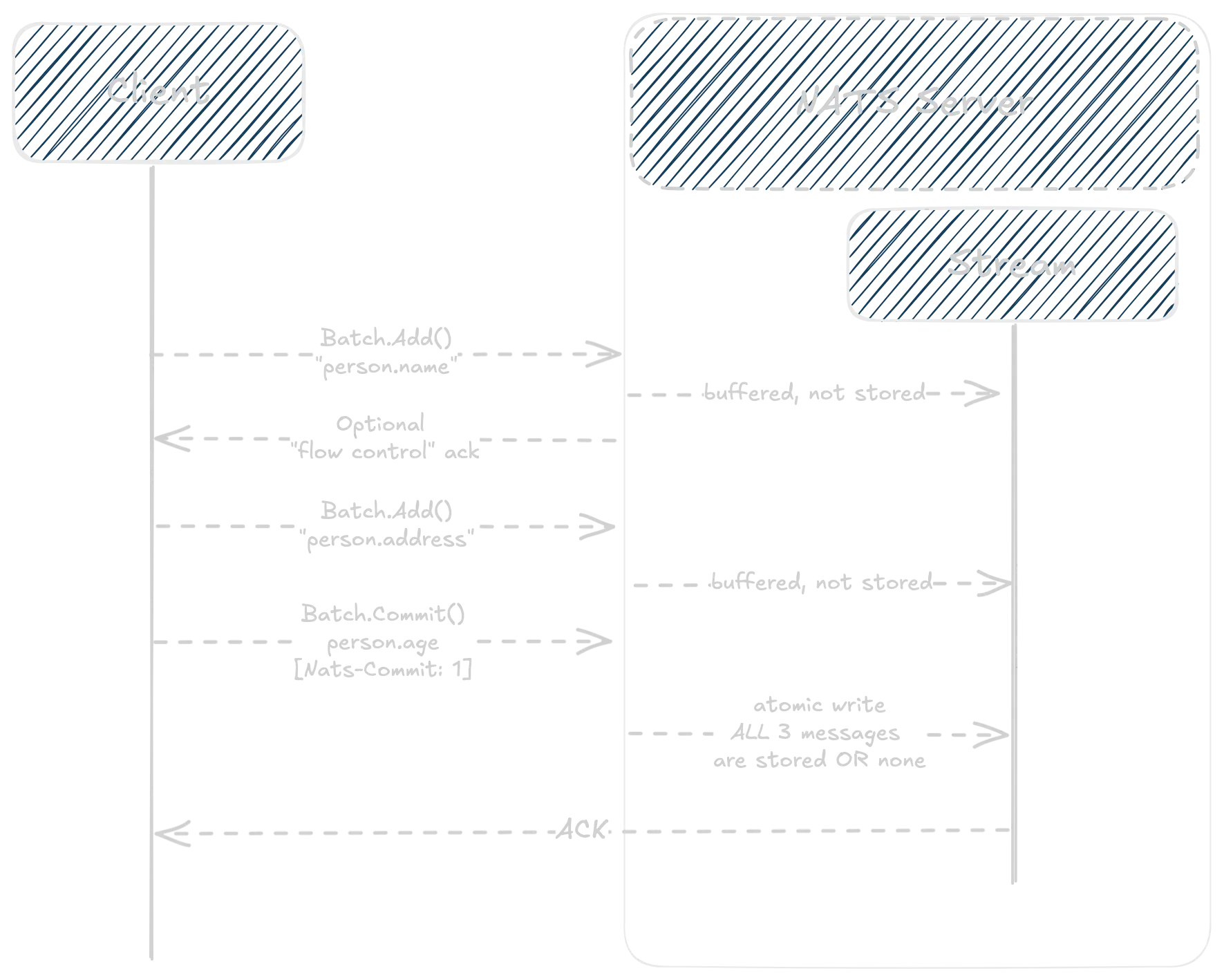
1// Atomic batch publishing - all or nothing2batch, err := jetstreamext.NewBatchPublisher(js)3if err != nil {4 return err5}6
7// Build your batch, messages are published immediately but not stored yet8batch.Add("person.name", []byte(`{"name": "John Doe"}`))9batch.Add("person.address", []byte(`{"address": "123 Main St"}`))10
11// Last message includes commit header - all messages succeed or all fail12ack, err := batch.Commit(ctx, "person.age", []byte(`{"age": 30}`))13if err != nil {14 // None of the messages were published15 return fmt.Errorf("batch publish failed: %w", err)16}17// All messages published successfully!In addition to atomicity, batch publishing can significantly reduce the number of round-trips to the server, improving performance in high-throughput scenarios. With large batches, you can configure flow control options to detect errors early and avoid sending unnecessary messages.
Batch Message Retrieval
The module also provides batch retrieval of messages from a stream, either by fetching N messages from given sequence (with optional filtering by subject) or fetching the last messages from the stream for a set of subjects.
When to use: When you need to efficiently retrieve multiple messages from a stream, especially with filtering by subject or starting from a specific sequence without a consumer. Ideal for log processing, data replay, or analytics scenarios. It can often be simpler and more efficient than using a consumer for ad-hoc retrieval.
When to avoid: For real-time message processing, work queue or interest-based scenarios, where consumers are more appropriate. Also, avoid for very large datasets where pagination or streaming consumers would be more efficient.
1// Fetch 100 messages starting from sequence 50, filtering by subject "orders.*"2msgs, err := jetstreamext.GetBatch(ctx, js, "ORDERS", 100, jetstreamext.GetBatchSeq(50), jetstreamext.GetBatchSubject("orders.*"))3if err != nil {4 return err5}6for msg, err := range msgs {7 fmt.Printf("%s: %s\n", msg.Subject, string(msg.Data))8}9
10// Efficiently fetch the last message for multiple subjects11lastMsgs, err := jetstreamext.GetLastMsgsFor(ctx, js, "METRICS",12 []string{"metrics.cpu.*", "metrics.memory.*", "metrics.disk.*"})13
14for msg, err := range lastMsgs {15 fmt.Printf("Latest %s: %s\n", msg.Subject, string(msg.Data))16}Connection and Monitoring
natscontext - Bridging CLI and Code
One of the most used nats CLI features is context management, allowing users to easily define and switch between different connection environments. Until recently, context files could only be used with the CLI. The natscontext module bridges this gap by allowing your Go applications to use the same contexts you’ve configured with the NATS CLI.
When to use: When you want to share connection configurations between NATS CLI and your applications, or when managing multiple environments (dev, staging, prod) with different credentials and settings.
When to avoid: For applications with hard-coded or centrally managed configurations, or when you need programmatic configuration that can’t be expressed in context files.
# Configure once with the CLInats context add production \ --server nats://nats.prod.example.com:4222 \ --creds /secure/prod.creds \ --js-domain PRODUCTION1// natscontext will read the context file and apply all settings2nc, settings, err := natscontext.Connect("production",3 nats.Name("prod-client"))4if err != nil {5 return err6}7
8// Get a JetStream handle using the domain in the context ("PRODUCTION")9js, err := jetstream.NewWithDomain(nc, settings.JSDomain)This approach eliminates configuration drift between your CLI tools and applications, making operations more consistent and less error-prone.
natssysclient - NATS Server Monitoring
The natssysclient module provides access to NATS server monitoring endpoints, allowing you to programmatically retrieve server and cluster metrics. It supports querying individual servers or the entire cluster, aggregating responses as needed.
When to use: When building monitoring dashboards, health check endpoints, or operational tools that need to inspect NATS server state. Great for custom observability solutions or automated operations.
When to avoid: If you’re already using Prometheus metrics or NATS surveyor - these may provide sufficient monitoring without custom code. Also, when needing real-time streaming of metrics, where subscribing to server events and advisories is more appropriate.
1// get VARZ from a specific server2varz, err := sys.Varz(ctx, "server_id", natssysclient.VarzEventOptions{})3if err != nil {4 // handle error5}6fmt.Println(varz.Varz.Name)7
8// get VARZ from all servers9// internally, this uses RequestMany from natsext module to gather responses10// from all servers in the cluster11varzs, err := sys.VarzPing(ctx, natssysclient.VarzEventOptions{})12if err != nil {13 // handle error14}15for _, v := range varzs {16 fmt.Println(v.Varz.Name)17}Ping endpoints return an iterator to allow non-blocking retrieval of monitoring data.
Although natssysclient does not yet cover all monitoring endpoints, we plan to expand it to provide full coverage in future releases.
Advanced Patterns: Solving Complex Problems
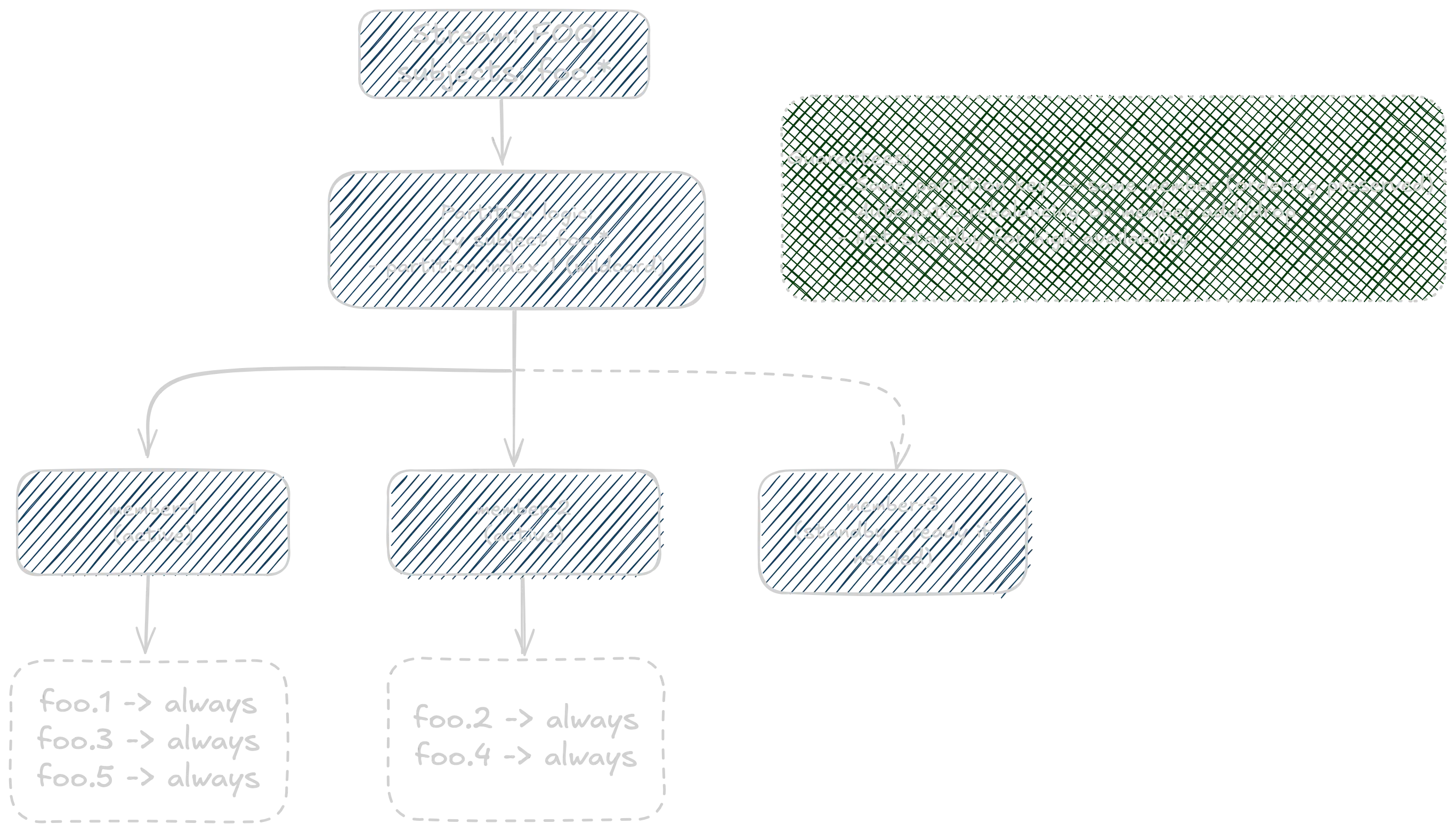
pcgroups - Partitioned Consumer Groups at Scale
The pcgroups module brings Kafka-style consumer groups to NATS, leveraging the server’s consumer priority policies, maintaining strict ordering guarantees.
When to use: When you have a stream and you want parallel consumption while preserving ordering per key/subject partition. Also, when you have workloads where the key partitioning logic naturally divides traffic by “key” (like per customer, per user, per device) and you don’t require global ordering across all keys.
When to avoid: When you require strict global ordering across all messages on stream (not just per key). Also, when your stream is relatively low-throughput or simple, and the overhead or complexity of partitioning is unnecessary.
It exposes two main modes: static and elastic membership. Static membership is ideal for scenarios where you have a fixed set of consumers, while elastic membership allows consumers to join and leave dynamically, with the group automatically rebalancing.
pcgroups exposes both API and CLI tools to manage consumer groups. Here’s an example of using CLI to create an elastic consumer group and then consuming messages with automatic rebalancing:
# create a consumer group with 10 max members, consuming from subject foo.* with partitioning on 'foo.<partition>' (index 1 in the subject)cg elastic create foo cons_group 10 'foo.*' 1
# start instances of the consumers in the group# at this point, consumer will not yet be assigned to the groupcg elastic consume foo cg member-1cg elastic consume foo cg member-2
# now add members member-1 and member-2 to the groupcg elastic add foo cg member-1 member-2At this point, members will be assigned partitions and start receiving messages.
The messages will be distributed evenly based on the partition key - each
partition key will always go to the same member, ensuring ordering guarantees.
For example, messages with subject foo.A will always go to member-1, foo.B to member-2
etc.
You can start more members at any time to increase parallelism or drop members to remove them from the group:
cg elastic add foo cg member-3cg elastic drop foo cg member-2Both static and elastic consumer groups can be created and managed programmatically as well, exposing same capabilities as the CLI.
What makes this special is the combination of horizontal scalability with strict ordering guarantees. Messages with the same partition key always go to the same consumer, ensuring you can scale out while maintaining business logic constraints.
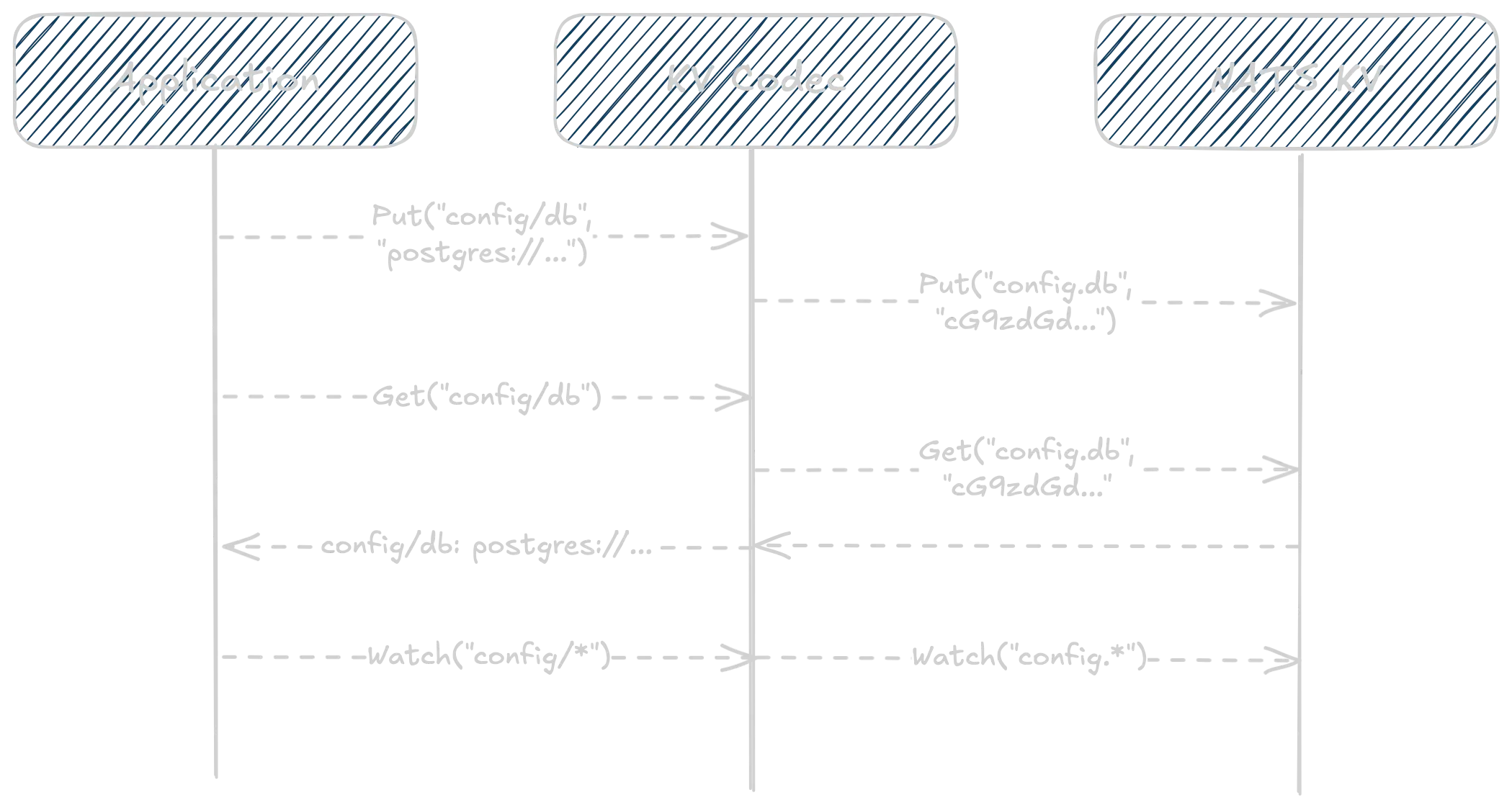
kvcodec - Transparent Encoding for KeyValue Stores
Working with JetStream KeyValue stores often requires encoding keys and values to handle special characters or implement encryption. The kvcodec module makes this transparent.
When to use: When your KV keys contain special characters (dots, spaces), need path-style notation, or require value encryption/compression. Ideal for configuration management or storing sensitive data.
When to avoid: If your keys are already NATS-compatible and values are simple strings or bytes - the standard KV interface is simpler. Also,
kvcodecis not suitable for type-aware key/value storage (e.g. working with structured data represented as JSON).
1// Create a KeyValue store, or access an existing one using nats.go2kv, _ := js.CreateKeyValue(ctx, jetstream.KeyValueConfig{3 Bucket: "APP_CONFIG",4})5
6// Path codec will transform keys like "/config/database/connection"7// into "config.database.connection" for storage in the KV store8pathCodec := kvcodec.PathCodec()9
10// Base64 codec will encode/decode values to/from base64 transparently11base64Codec := kvcodec.Base64Codec()12
13// create an encoded kv instance with path-based keys and base64-encoded values14codecKV := kvcodec.New(kv, pathCodec, base64Codec)15
16// codecKV implements the same KeyValue interface, but keys and values17// are automatically encoded/decoded18err := codecKV.Put(ctx, "/config/database/connection",19 []byte("postgres://localhost/myapp"))20if err != nil {21 return err22}23
24// Watch with wildcards still works!25watcher, _ := codecKV.Watch(ctx, "/config/database/*")26for entry := range watcher.Updates() {27 fmt.Printf("Config update: %s = %s\n",28 entry.Key(), string(entry.Value()))29}The beauty here is that your application code remains clean and intuitive while the codec handles all the complexity behind the scenes.
In addition to a few pre-defined codecs, you can implement your own codec to handle custom encoding/decoding logic, such as encryption or compression. It’s as simple as implementing the kvcodec.Codec interface.
counters - Distributed Counting
The new counters module leverages NATS 2.12’s counter functionality to provide distributed counting across mirrors and sources.
When to use: When you need distributed counters with exact counts, source tracking for audit trails, or aggregation across multiple data centers. Perfect for metrics and usage tracking.
When to avoid: When working with non-integer values or when the stream should hold additional message data beyond counting.
1// Create a counter-enabled stream2plStream, _ := js.CreateStream(ctx, jetstream.StreamConfig{3 Name: "VIEWS_PL",4 Subjects: []string{"views.pl"},5 AllowMsgCounter: true, // Enable counter functionality6 AllowDirect: true, // Required for reading7})8
9counter, _ := counters.NewCounterFromStream(js, plStream)10
11// Increment from multiple sources simultaneously12counter.AddInt(ctx, "views.pl", 1)13counter.AddInt(ctx, "views.pl", 5)14
15// load counter value16value, _ := counter.Load(ctx, "views.pl")17fmt.Printf("Total views: %s\n", value.String())Additionally, counters will work across sources and mirrors, allowing you to aggregate counts from multiple services or data centers seamlessly.
1euStream, _ := js.CreateStream(ctx, jetstream.StreamConfig{2 Name: "VIEWS_EU",3 Subjects: []string{"views.eu"},4 AllowMsgCounter: true,5 AllowDirect: true,6 Sources: []*jetstream.StreamSource{7 {8 Name: "COUNT_PL",9 SubjectTransforms: []jetstream.SubjectTransformConfig{10 {Source: "views.pl", Destination: "views.eu"},11 },12 },13 {14 Name: "COUNT_ES",15 SubjectTransforms: []jetstream.SubjectTransformConfig{16 {Source: "views.es", Destination: "views.eu"},17 },18 },19 },20 }21
22euCounter, _ := counters.NewCounterFromStream(js, euStream)23
24// you can load the full counter entry, including source history for auditing25entry, _ := euCounter.Get(ctx, "views.eu")26fmt.Printf("Total views: %s\n", entry.Val.String())27for source, val := range entry.Sources {28 fmt.Printf(" Source %s: %s\n", source, val.String())29}The source tracking capability is particularly powerful for audit trails and debugging. You can see exactly which service instances contributed to each counter value, making it easy to track the flow of data.
Looking Forward
orbit.go represents our commitment to rapid innovation in the NATS ecosystem for Go developers. By providing a space where client-side abstractions can evolve quickly, we’re enabling NATS Go developers to experiment with new patterns and provide feedback, further refining these abstractions.
As the NATS server continues to add new powerful primitives – like the counters and atomic batch publishing in 2.12 – you can expect more orbit modules to expose these capabilities through intuitive, high-level abstractions.
The modular nature of orbit.go means you can adopt new capabilities incrementally. Start with what you need today, and as your requirements grow, additional modules can be added with a single import. Each module is independently versioned, so you can rely on stable APIs once they reach v1.0.0, while still having access to cutting-edge features in pre-1.0 modules.
Get Involved
The entire Orbit ecosystem is open source and welcomes contributions. Whether you’re building a new abstraction for orbit.go, improving existing modules, or even porting successful patterns to other Orbit implementations, your input helps shape the future of NATS client libraries.
Visit the orbit.go repository to explore the Go implementation, and don’t hesitate to open issues or pull requests – we’re excited to collaborate with the community to make Orbit a success!
And don’t forget to check out other Orbit libraries: orbit.java orbit.js orbit.rs orbit.net
Related posts
All posts