MQTT vs. NATS for Fleet Management: Hub-and-Spoke vs. Distributed Mesh


Choosing between MQTT and NATS is less about protocol features and more about how the system behaves when networks are unreliable, devices are distributed, and operations have to continue at the edge. MQTT is built around a central broker. NATS is built as a distributed mesh. That architectural difference shapes everything downstream.
Consider a refrigerated truck crossing a rural stretch with no cellular signal. The compressor temperature spikes. The onboard system needs to alert the driver, log the event, and eventually sync with the cloud. How the messaging layer handles that moment — locally or through a central broker — defines whether the driver gets the alert in seconds or only after the truck is back in range.
Why topology matters more than features
What looks like a protocol choice quickly becomes an operations choice. A centralized design changes what happens during disconnects, how local systems communicate, where state lives, and how much infrastructure accumulates around the messaging layer.
That is how fleet architectures end up running MQTT for device telemetry, Kafka for durable streams, gRPC for request-reply, and Redis for shared state. Each tool solves a real problem. Each one also adds deployment overhead, monitoring surface, and another failure mode to debug at 2 AM. The bigger issue over time is not any single missing capability — it is the complexity of stitching four systems together.
How MQTT handles the edge
The hub-and-spoke constraint
Every MQTT message from a field device travels to a central broker before routing anywhere else — the network trombone effect.
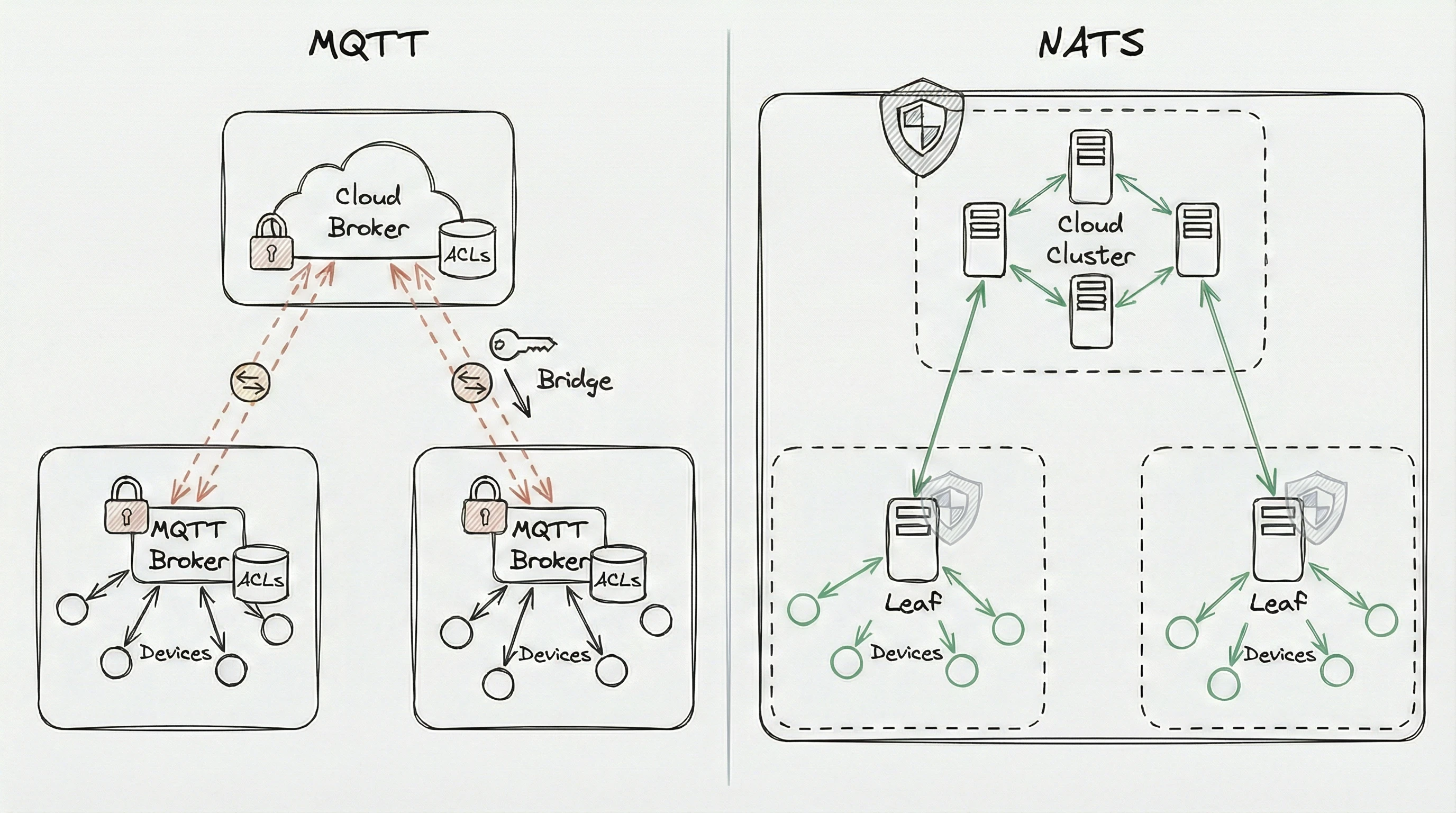
Picture a site with 30 edge nodes coordinating local operations. Every message travels to a cloud broker and back, even when the publisher and subscriber sit on the same local network. Deploying a local MQTT broker solves the latency problem but creates a separate instance with its own configuration, ACLs, and monitoring. Bridge it to the cloud broker and that’s another integration point. Across 200 sites, each with its own local broker config, the operational surface area adds up fast.
State management is thin
MQTT provides retained messages (the broker stores the last message per topic) and persistent sessions for QoS 1/2 delivery. These cover basic reconnection and last-known-value lookups.
There’s no native concept of a message stream, though. No built-in way to store a historical window or replay telemetry. Retaining a week of sensor diagnostics, querying 1,000 telemetry readings, or reliably queuing commands requires bolting on an external database or streaming system alongside the broker.
Delivery reliability has a structural gap
MQTT expects clients to acknowledge receipt, not processing completion. A microservice receives a message, then crashes before finishing the work — that message is gone. Delaying acknowledgment until processing completes fights the protocol’s design assumptions and reduces throughput significantly.
QoS 1 can also deliver duplicates after network interruptions, which means every downstream consumer needs deduplication logic. At scale, teams end up layering on custom retry queues, deduplication filters, and dead-letter handling. Each layer introduces its own failure modes.
Vendor-specific behavior
Subscribing is straightforward — topics like fleet/device-01/telemetry/sensors with wildcards. Rerouting or rewriting topics, however, relies on broker-specific features (rule engines, extensions, plugins) that vary by vendor and don’t transfer between implementations.
QoS behavior has a similar problem. MQTT defines QoS 0/1/2 at the spec level, but actual guarantees differ across broker and client stacks.
Federation gets complicated
Scaling MQTT across multiple sites or regions requires careful federation configuration to avoid message loops, duplicates, and inconsistent topic namespaces. Messages published in one region may traverse multiple broker hops before reaching subscribers elsewhere, adding latency and failure points.
Topic mappings, access controls, and monitoring across federated MQTT brokers become a dedicated operational workstream. Bridges can lose messages during disruptions or restarts — gaps that may go undetected until downstream systems surface missing data.
Stream processing requires external systems
MQTT handles routing well but lacks native stream processing. Aggregating sensor data, performing windowed calculations, or maintaining stateful transformations requires external frameworks like Kafka or Flink. That means deploying and managing additional systems with different semantics and failure modes.
NATS JetStream doesn’t replace specialized processors like Flink for complex aggregations. But it eliminates the need for a separate durable log system alongside the broker — one system instead of two for common fleet pipelines.
How NATS handles the edge
NATS operates as a connective fabric rather than a central box. The difference becomes clearest in edge deployments.
Leaf nodes
Any edge device can run its own local NATS server as a leaf node. The node handles all local traffic between sensors, controllers, and colocated applications. When cellular connectivity exists, the leaf node bridges to the cloud transparently. When connectivity drops, local operations continue. Messages destined for the cloud queue up and sync automatically when the connection returns.
Back to the refrigerated truck: a local NATS leaf node means onboard systems keep communicating normally. Sensor data persists to a local JetStream stream. The driver gets the compressor alert immediately. When cellular comes back, the leaf node synchronizes with the cloud — messages arrive in order, without duplication, without application-level reconciliation code.
Same binary, same configuration patterns, same security model at the edge and in the cloud.
Subject mapping
NATS uses dot-separated subjects like fleet.device01.telemetry.sensors. Subject mapping transforms or redirects data streams without touching device code. Need to route all sensor telemetry to a new analytics service? Add a mapping rule at the server level. No firmware updates required.
This works identically across every NATS server, including edge leaf nodes.
Unified transport
NATS combines pub/sub, request/reply, and distributed persistence (JetStream) into a single protocol. No sidecar database for message survival through reboots. No separate RPC framework for command-and-control. One binary, one protocol, one set of operational procedures.
Security at 100,000 devices
Managing credentials for a handful of servers is a different problem than managing them across a distributed fleet where devices get compromised, edge nodes get decommissioned, and credentials need rotation without downtime.
Where MQTT’s model strains
Standard MQTT deployments use TLS for transport and username/password or client certificates for identity.
The most common authentication path — username and password — transmits credentials over the encrypted channel. If TLS gets skipped for constrained devices, credentials travel unprotected. Client certificates provide stronger authentication but add lifecycle management overhead across large fleets.
ACLs are typically centralized. The broker maintains which clients can publish or subscribe to which topics. At 100,000 devices, that list becomes difficult to manage. Every permission change — onboarding a new device, rotating credentials, adjusting topic access — requires updating a central store.
In multi-region setups, each broker maintains its own ACL store. Revoking credentials in one region requires propagation to every other broker. Until that completes, revoked credentials remain valid at those sites.
How NATS approaches identity
NATS uses a decentralized security model based on NKeys (Ed25519 cryptographic keys) and JWTs. The private key never leaves the device. Identity is proven through cryptographic challenge-response, not credential transmission.
When a device connects, it signs a server challenge with its private key. The server only needs the public key to verify. If an attacker intercepts the connection, they gain nothing useful. If the server itself is compromised, attackers still can’t impersonate devices because they don’t have the private keys.
JWTs encode permissions directly. A device’s JWT might specify it can publish to telemetry.deviceA.* and subscribe to commands.deviceA.*. These permissions are signed by an account key and can’t be forged. The server validates the JWT signature and enforces permissions without consulting an external database.
Multi-tenancy is straightforward. Different fleets or departments share the same NATS infrastructure with complete data isolation. Each account has its own signing key and permission boundaries. A device in Fleet A cannot see or interact with Fleet B’s subjects, even when connected to the same server.
Credential revocation is targeted and immediate. Add a device’s public key to a revocation list and access is cut across the entire cluster — including leaf nodes — within seconds. No restarts. No database updates. The compromised device loses access; everything else continues normally.
Telemetry and command patterns
Getting data in
Fleet devices generate substantial data: sensor readings, GPS coordinates, operational metrics, environmental telemetry, system diagnostics. Some require real-time processing. Some need storage for later analysis. Some must be retained for regulatory compliance.
The MQTT data path. Full-featured client libraries like Eclipse Paho support persistent offline queuing, and session expiry mechanisms handle reconnection. But on constrained edge hardware — microcontrollers, industrial gateways, embedded devices common in fleet environments — lightweight MQTT clients often lack durable buffering. Connectivity drops and unsent messages vanish. Power cycles can corrupt any local message queue.
High-volume telemetry often requires bridging to Kafka for durable storage. The broker handles real-time routing; Kafka handles persistence and replay. That works, but it means operating two systems with different semantics and failure modes. The integration layer between them becomes another component to monitor and debug. When messages fail to bridge, diagnosing whether the problem is in the broker, bridge component, or Kafka cluster requires expertise across all three.
The NATS data path. JetStream integrates persistence directly. When a device publishes telemetry, data can simultaneously reach real-time consumers and land in a stream for later processing. Streams support retention policies — last 7 days, last 10GB, or matching criteria — and replicate across multiple servers for durability.
Pull consumers change the model. Instead of the system pushing data and potentially overwhelming backend services, consumers pull messages at their own pace. A batch analytics job requests 1,000 messages, processes them, requests the next batch. If the job crashes, it resumes from where it stopped.
NATS is a single binary under 20MB. It runs on a Raspberry Pi or an industrial gateway — hardware where Java-based brokers or Kafka instances would never fit. That makes it practical to deploy real persistence at the edge, not just in the cloud.
Sending commands back
Sending a command to a specific device and getting a response sounds simple. In practice, it requires correlation IDs, temporary response topics, timeout handling, and retry logic. MQTT 5.0 added response topic and correlation data properties to standardize request/reply, but developers still manage response routing and timeout logic themselves.
NATS treats request/reply as a first-class operation. Send a configuration command to an edge node. NATS creates a temporary inbox for the response, routes the command, delivers the response back. Correlation and routing happen at the protocol level.
Offline commands work naturally with JetStream. If a device loses connectivity when a command is sent, the command sits in a stream. When the device reconnects and subscribes to its command subject, the message is waiting.
Fan-out works as expected for pub/sub — devices subscribe to commands.fleet.firmware and a single publish reaches all of them. Combined with JetStream, devices that are offline when the update is published receive it when they reconnect, without the sender needing to track delivery state per device.
Performance and scalability
| Feature | MQTT (v5.0) | NATS (with JetStream) |
|---|---|---|
| Topology | Hub-and-Spoke | Distributed Mesh / Leaf Nodes |
| Throughput | Broker dependent | 10M+ msg/sec single server; scales horizontally |
| Persistence | Requires external DB | Native (JetStream) |
| Security | Centralized ACLs / TLS | Decentralized JWT / NKeys |
| Latency | Low (deployment dependent) | Sub-millisecond (p99) |
| Communication | Pub/Sub, Req/Reply (v5.0) | Pub/Sub, Req/Reply, Key-Value, Object Store |
Raw throughput benchmarks vary widely by broker, payload size, and test conditions — making direct comparisons misleading. What matters more for fleet deployments is where the processing happens. When messages traverse centralized cloud brokers, even fast MQTT implementations add network round-trip time that dwarfs protocol-level differences. A locally deployed NATS leaf node processing edge traffic eliminates that round-trip for local operations while syncing to the cloud asynchronously.
NATS single-server throughput exceeds 10 million messages per second, with sub-millisecond p99 latency in production. Most fleet applications won’t approach these limits, but the headroom means fewer servers and better spike handling.
Scaling MQTT typically means clustering brokers behind load balancers, which introduces session affinity requirements, shared subscription state complexity, and network partition handling that varies by vendor.
NATS servers discover each other through gossip protocols and form clusters automatically. A server fails, clients reconnect to another cluster member without message loss (with JetStream persistence). Adding capacity means starting new servers and letting them join. Removing capacity means draining connections and shutting down.
For global deployments, Synadia Cloud provides a managed supercluster with worldwide points of presence. Edge devices connect to the nearest location and NATS handles global routing automatically.
Working with legacy MQTT infrastructure
Most fleet teams don’t start from scratch. Existing hardware runs MQTT clients that can’t be easily updated. Backend systems expect MQTT topics.
The NATS server speaks MQTT natively — MQTT is one of several client-facing protocols (alongside the NATS native protocol and WebSocket) that all feed into the same unified messaging substrate. An MQTT client publishes to a topic, and the NATS server translates it into native NATS messaging. A legacy sensor publishing to fleet/device01/temperature appears on the NATS side as fleet.device01.temperature, and vice versa.
This is not a standalone broker that happens to be co-located. MQTT semantics — retained messages, sessions, QoS delivery guarantees — are implemented on top of JetStream. That means MQTT workloads automatically get the full NATS infrastructure: clustering, leaf nodes, security, multi-tenancy, and subject mapping.
This keeps MQTT at the very edge, on simple sensors or legacy gateways, while NATS handles everything else. A modern microservice subscribes to NATS subjects and receives messages from both MQTT and native NATS clients without distinguishing the source. New devices use native NATS clients, legacy devices continue with MQTT, both participate in the same messaging fabric.
The real decision
The protocol question resolves quickly. MQTT is a fine last-mile protocol for constrained sensors. NATS is the infrastructure that ties everything together.
The harder question is whether your fleet architecture can tolerate the operational weight of running separate systems for messaging, streaming, persistence, and security, or whether collapsing those into a single system changes what’s possible at the edge. That’s not a feature comparison. It’s an infrastructure strategy decision, and it compounds with every site you add.
Frequently Asked Questions
How do I migrate from MQTT to NATS for IoT fleet management?
The NATS server speaks MQTT natively — MQTT clients connect directly to a NATS server without code changes or a separate broker. MQTT is a protocol interface into the NATS system, not a standalone broker, so MQTT workloads get clustering, leaf nodes, security, and multi-tenancy for free. This allows incremental migration one fleet segment at a time. Legacy MQTT devices and new NATS-native devices coexist on the same server during the transition. NATS MQTT configuration
How does NATS compare to MQTT and Kafka for edge computing use cases?
NATS is a lightweight, edge-native system combining pub/sub, request-reply, and persistent streaming in a single ~20MB binary. Kafka provides high-throughput stream replay and processing but is designed for datacenter deployments with significant resource requirements. MQTT offers minimal-footprint sensor telemetry but lacks native persistence and request-reply. NATS is the only system designed to run identically at both edge and cloud on the same infrastructure. Compare NATS and Kafka
Last updated: February 2026
Ready to build your distributed mesh architecture? Partner with the NATS experts at Synadia to get your fleet deployed faster.
Related posts
All posts


