
In this blog, I’ll review how NATS makes operating distributed AI applications more efficient.
Saving money with AI inference at the edge
AI inference at the edge is increasingly possible thanks to GPUs on edge devices. Those GPUs may be a significant investment, but, paired with NATS.io, they offer serious efficiencies and ROI.
- Lower networking costs: Inference processing at the end allows one to send only the low-volume but high-value events identified through inference to the cloud rather than the high-volume raw data, as networking to and from the edge can be expensive (including cloud egress and ingress charges).
- Faster response time: Doing inference at the edge means you can also react to the threats and opportunities uncovered through that inference locally instead of waiting for cloud round-trips. For many use cases, this latency reduction translates to real financial impact..
- Scalability: Inference capacity scales automatically with edge deployment growth, no need to grow central infrastructure.
- Privacy and compliance: Doing AI inference directly at the edge means raw data - especially PII - doesn’t have to leave the edge, reducing regulatory burden, risks, and associated costs.
Saving and Generating Money when doing AI Inference in the Cloud:
NATS.io is increasingly being used as a critical infrastructure by companies doing AI inference in the cloud at scale - including the operators of the world’s largest distributed GPU cluster spread across 73 countries https://x.com/inference_net/status/1883293387719409884 rely on NATS to intelligently route inference requests, with direct impact on both performance and cost.
In these deployments, NATS.io is used to transmit and intelligently distribute requests for inference from the external-facing API servers to the hosts with (expensive) GPUs doing the actual inferencing calculations. Two key NATS features are central here:
-
Distributed request/reply for low-latency, interactive inference.
-
CQRS-like distributed processing with Streams, used as dynamic work queues.
Why Latency Matters
Service latency - especially “Time To First Token” - is critical and a primary metric of customer service. When offering a global AI inference service, in order to keep this latency in check, providers deploy multiple customer service points of presence in multiple regions of the world (and some times from different hyperscalers) such that customer requests (i.e. prompts) are directed to the closest regional point of presence, for example through DNS redirection services such as Route53.
The API gateways in a region will then send those prompts to the GPUs located in the same region, for example by leveraging NATS.io’s request/reply functionality.
So far so good, this allows you to do AI inference distribution to your GPUs with geo-affinity and fault-tolerance (if all the GPUs in a region go down, the requests being transparently routed to other regions over the NATS.io Super-Cluster). However, you cannot control the usage patterns of your customers: at any given point you may have a burst of requests being sent by the customers in one region, and very few requests sent by customers in another region. This means that customers in one region see increased latency, while you have GPUs sitting idle in another region.
New in NATS 2.11: Priority Groups
And now, thanks to the new ‘priority groups’ features introduced starting with version 2.11, NATS.io can now go, and can have a direct impact on the bottom line.
These new features mean that you can go beyond simple distributed request/reply with geo-affinity and allow for the requests piling up in the work queue stream for one region to be automatically and transparently consumed by workers in other regions:
- Overflow handling: excess requests in one region’s queue can be transparently offloaded to GPUs in other regions.
- Prioritization policies: workloads can flow according to business-defined priorities.
This ensures higher GPU utilization across the fleet while keeping latency (including tail latencies) in check.
The Utilization Challenge
The higher utilization of the expensive computing infrastructure that you rent, while increasing customer satisfaction by keeping Time To First Token latencies in check (especially tail latencies) can have a direct impact on your infrastructure costs as you may not need to rent as many GPUs per region in order to meet your SLAs (you don’t need to ‘size for the peaks’ as much as you would otherwise), and give you a competitive advantage over competitors.
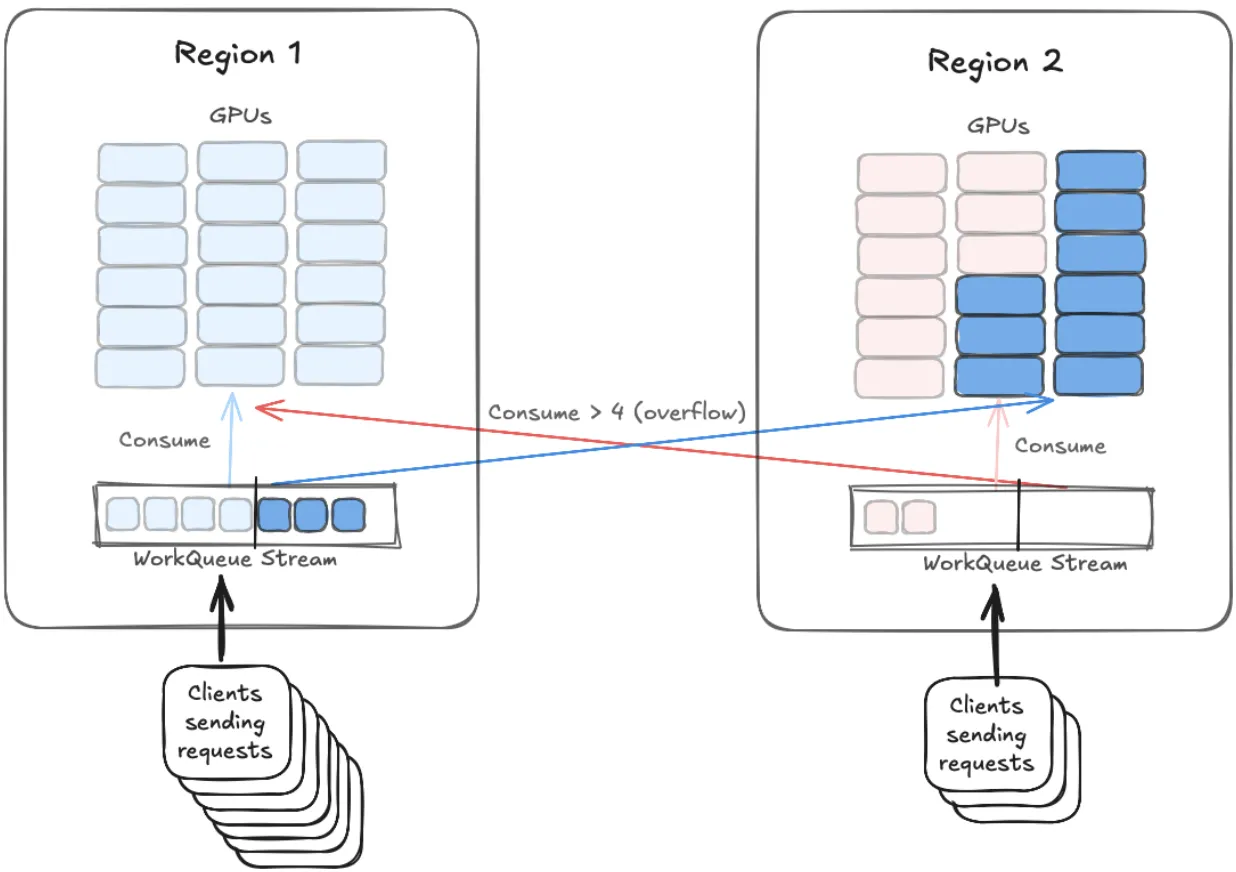
Diagram showing overflow consumption from a stream used as a work queue between two regions (can be expanded to more than two regions).
Direct Business Impact
Cloud inference brings its own challenges: expensive GPUs, unpredictable customer demand, and strict latency expectations. NATS helps organizations turn those challenges into opportunities by enabling intelligent request routing, workload overflow handling, and efficient utilization of global GPU fleets.
For providers, this translates to:
- Lower infrastructure costs: fewer idle GPUs, and less over-provisioning to “size for peak.”
- Improved customer satisfaction: consistently low latency, even during traffic bursts.
- Competitive advantage: better economics and user experience than competitors.
In short, NATS helps inference providers balance performance, cost, and scalability—turning unpredictable workloads into opportunities.
Related posts
All posts


